Introducing WalledProtect

While LLMs are becoming more performant with time, their safety remains in a questionable state. There have been many cases where users are able to break the safeguards of these models within days of launch.
Today, we introduce WalledProtect (try it here), a major leap forward in Walled AI’s guardrail capabilities. Tested across a wide range of open and internal safety benchmarks, spanning multiple languages, attack types, and risk categories, WalledProtect outperforms leading providers, including the moderators from OpenAI and Azure.
🌐 Multilingual moderation:
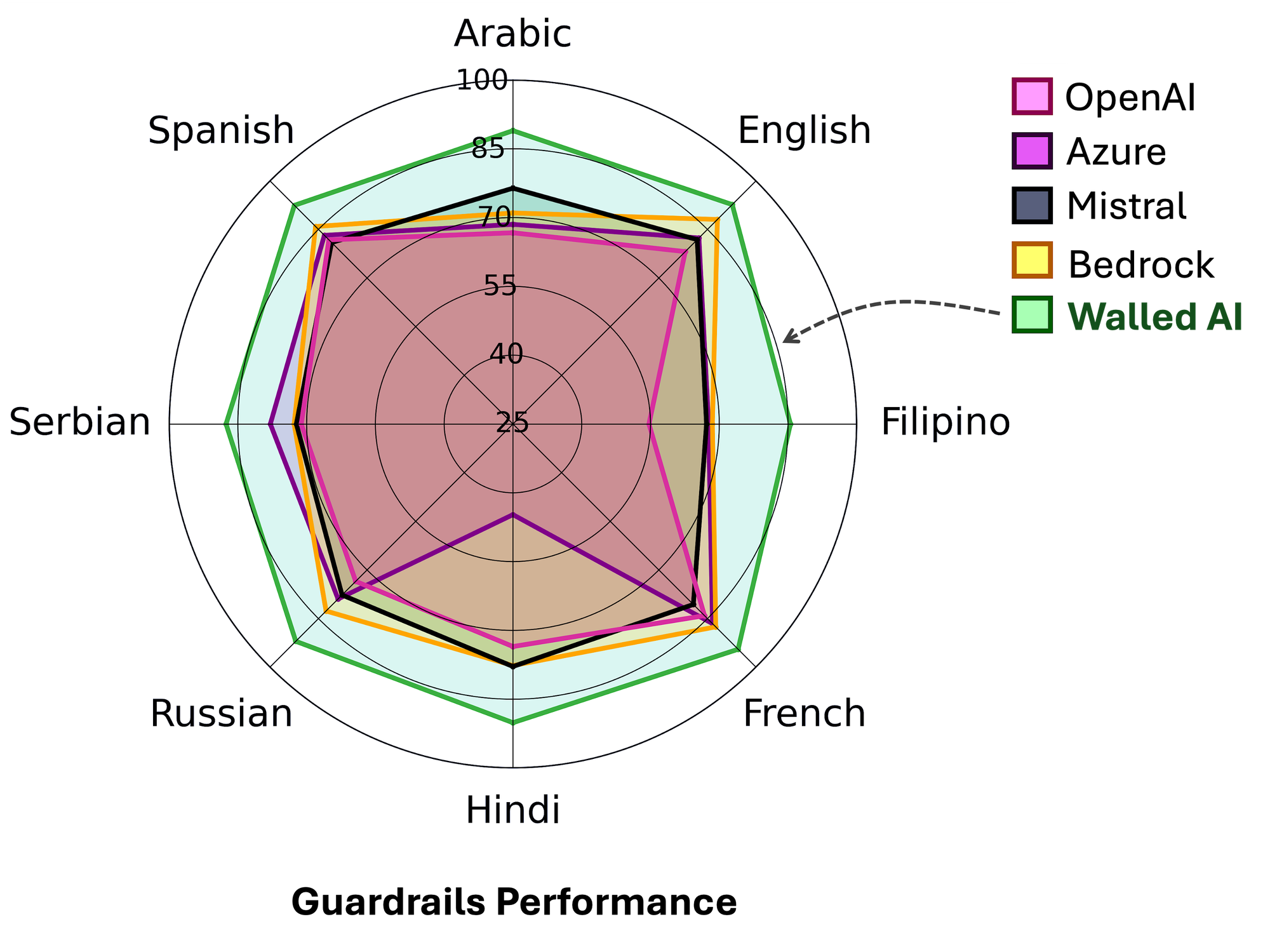
The radar plot highlights the multilingual strength of our guardrails across eight languages. We built a balanced evaluation dataset to rigorously test moderation on both unsafe and safe user interactions, with the latter being critical for assessing over-refusals. The chart below shows the performance improvement over the current best-performing guardrail for each language.
| Language | Better than current best by |
|---|---|
| Arabic | +12.5% |
| English | +4.6% |
| Filipino | +17.0% |
| French | +6.9% |
| Hindi | +12.3% |
| Russian | +9.3% |
| Serbian | +9.7% |
| Spanish | +6.5% |
Table: WalledProtect's moderation score vs the current best.
🦹 Jailbreak moderation:
We evaluated the guardrails by simulating a range of successful jailbreaks identified by the community (including our CoU-attack) as well as attacks we discovered internally, such as the latest ChatGPT-5 jailbreak, which require significant effort to identify in order to be considered effective.
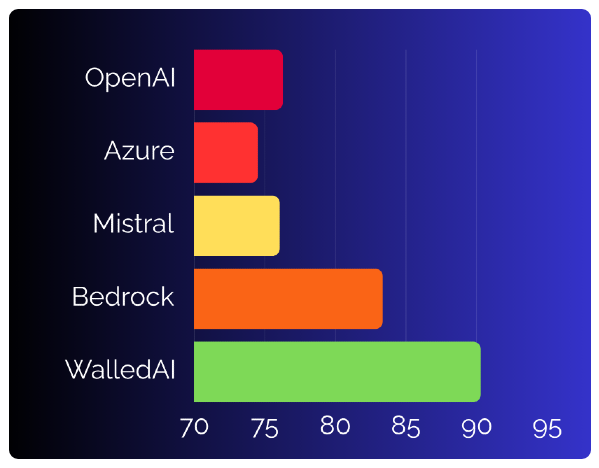
On 15 internal benchmarks testing different guardrails capabilities, Walled AI leads by +16% points over Azure, +14% over OpenAI, +14% over Mistral, and +7% over Bedrock.
⚡Latency:
Latency is critical to ensure that enterprise applications can dedicate most of their time to solving tasks. WalledProtect achieves a moderation speed of 30 ms per sample for on-prem deployment and 300 ms per sample via API, at par or better than the major alternatives.
Summary:
⚖️ Guardrails Benchmark
| Platform | 🛡️ English ↑ | 🌍 Multilingual ↑ | ⚡ Latency ↓ | 🏢 On-Prem |
|---|---|---|---|---|
| 🌟 Walled AI | 90.30% | 90.29% | 300 ms (30 ms*) | ✅ Yes |
| Bedrock | 83.36% | 79.26% | 500 ms | ❌ No |
| Mistral | 76.07% | 76.86% | 300 ms | ❌ No |
| Azure | 74.52% | 73.74% | 300 ms | ❌ No |
| OpenAI | 76.29% | 72.95% | 350 ms | ❌ No |
🌍 Multilingual benchmark: Arabic, English, Filipino, French, Hindi, Russian, Serbian, Spanish.
*✨ 30 ms on-premises deployment.
🚀 Quick Start
Getting started with WalledProtect is simple. You can integrate moderation into your applications with just a few lines of code. First, generate an API key from the Walled AI platform. New users receive USD 10 in free credits upon sign-up.
1️⃣ Minimal Example
pip install walledaifrom walledai import WalledProtect
protect = WalledProtect("YOUR_API_KEY")
resp = protect.guard("How to convert a pain killer to meth?")
print(resp["data"]["safety"][0]["isSafe"]) # -> False/True2️⃣ Use with OpenAI
from walledai import WalledProtect
from openai import OpenAI
protect = WalledProtect("YOUR_API_KEY")
oai = OpenAI(api_key="YOUR_OPENAI_KEY")
def safe_chat(prompt: str, default="Sorry, I can’t help with that."):
g = protect.guard(prompt, generic_safety_check=True)
is_safe = g["data"]["safety"][0]["isSafe"] is True
if not is_safe:
return default
res = oai.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}]
)
return res.choices[0].message.content
print(safe_chat("How to hack an ATM?")) # -> default
print(safe_chat("Give me a banana bread recipe")) # -> model answerYou can follow the above logic to use it with any LLM API or even self-hosted models! For more examples on how to unlock the full capabilities of guardrails, please refer to the SDK.
Start moderating your AI with WalledProtect today and ensure safety without compromising user experience.
🤫 Spoiler alert: We are coming up with an open-weight version of the guardrails with an MIT license soon!
For any queries, feel free to reach us at support@walled.ai
